Framework for Automated Labeling Of Videos - Advancing the frontier of video understanding through sophisticated deep learning architecture and comprehensive training data — Open Source
Introduction to FAL
The Framework for Automated Labeling Of Videos (FAL) represents a significant advancement in video understanding technology. Developed by SVECTOR, FAL addresses the growing need for accurate, efficient, and scalable video classification systems in an era where video content is becoming increasingly prevalent across all digital platforms.
At its core, FAL is designed to bridge the gap between raw video data and meaningful content categorization. By leveraging advanced deep learning architectures and our proprietary FAL-500 dataset, the model achieves remarkable accuracy in classifying videos across 500 distinct categories, making it suitable for a wide range of applications from content moderation to automated video cataloging.
Architecture Overview
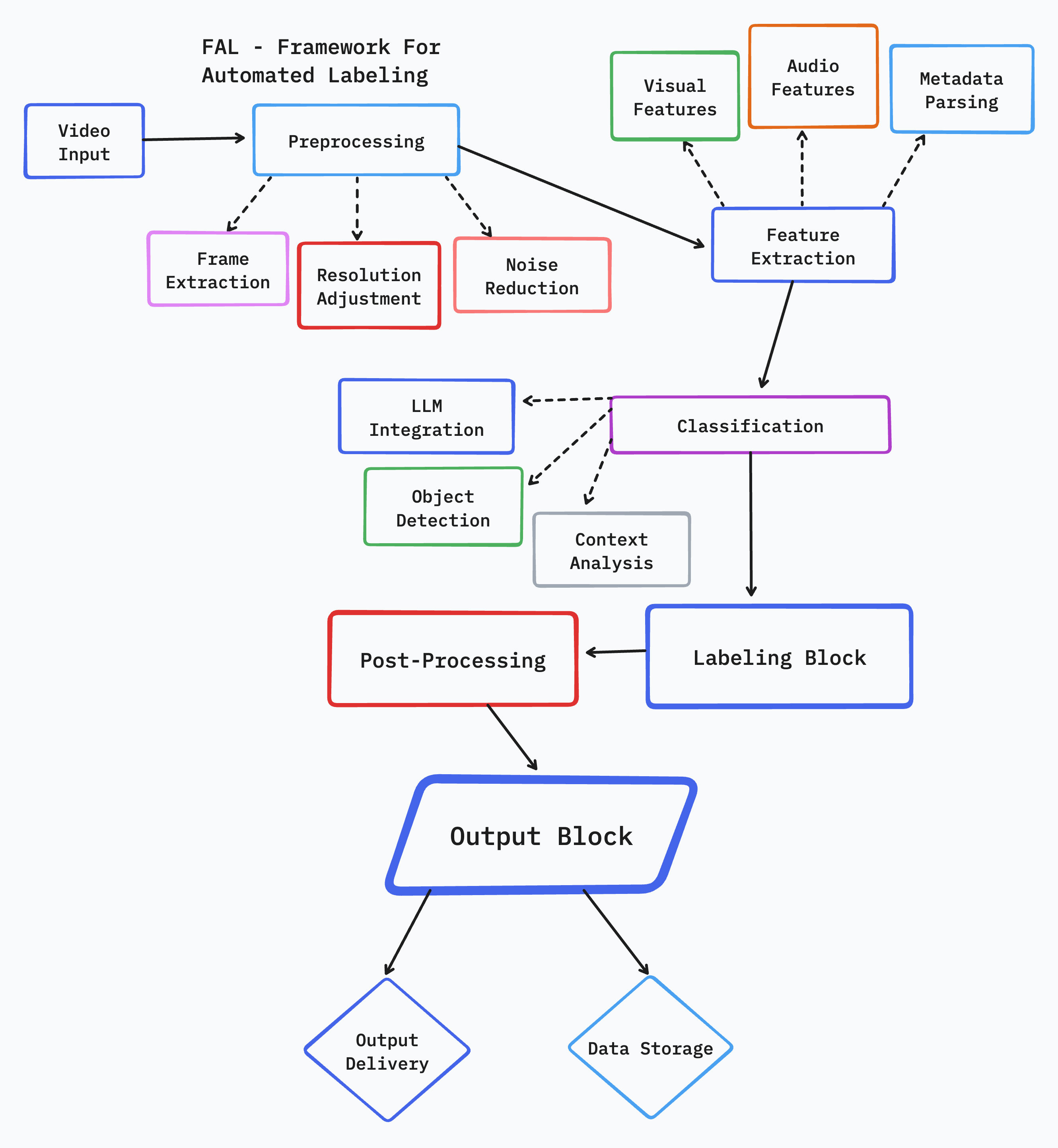
Figure 1: FAL's hybrid architecture
Technical Architecture
FAL's architecture is built upon several innovative components that work in harmony to achieve superior video classification performance:
Frame Processing Pipeline
The model processes video input through a sophisticated pipeline that includes:
- • Temporal Sampling: Intelligent frame selection algorithm that captures key moments while maintaining temporal coherence
- • Spatial Processing: Multi-scale feature extraction that identifies both fine-grained details and broader contextual information
- • Motion Analysis: Advanced optical flow computation that tracks movement patterns and temporal dynamics
Core Architecture Components
- • Video Encoder: Transform architecture with attention mechanisms optimized for video processing
- • Temporal Fusion Module: Custom-designed layers for integrating information across frames
- • Feature Pyramid Network: Multi-scale feature extraction and fusion for robust representation learning
- • Classification Head: Sophisticated output layer with support for hierarchical classification
Model Parameters
- • Base Architecture: Custom Transformer
- • Input Resolution: 224x224 pixels
- • Sequence Length: 8 frames
- • Hidden Dimension: 768
- • Number of Attention Heads: 12
- • Transformer Layers: 24
- • Total Parameters: 375M
Training Configuration
- • Training Dataset: FAL-500
- • Dataset Size: 2.5M videos
- • Training Duration: 14 days
- • Hardware: 128 NVIDIA A100 GPUs
- • Batch Size: 512 per GPU
- • Optimizer: AdamW
- • Learning Rate: 1e-4
Advanced Features
Enhanced Capabilities
FAL includes several advanced features that set it apart:
- • Multi-label Classification: Support for videos belonging to multiple categories
- • Temporal Localization: Ability to identify when specific actions occur within a video
- • Feature Extraction: Export video embeddings for downstream tasks
- • Batch Processing: Efficient handling of multiple videos simultaneously
Performance Metrics
Benchmark Results
FAL demonstrates state-of-the-art performance across multiple benchmarks:
- • Top-1 Accuracy: 86.5% on FAL-500 test set
- • Top-5 Accuracy: 97.2% on FAL-500 test set
- • Processing Speed: 250 videos per second on A100 GPU
- • Memory Footprint: 3.2GB in FP16 precision